开源+免费=无敌,跟风学习deepseek,拥抱AI,玩起来~
花了一天时间完成本地部署deepseek,总结出以下几个问题,写一篇笔记记录过程。
问题一:为什么不直接使用网页版DeepSeek?
问题二:本地部署DeepSeek有哪些优势?
问题三:为什么要使用RAG技术?RAG和模型微调的区别?
RAG(Retrieval-Augmented Generation)的原理:
RAG和模型微调的区别?
问题四:什么是Embedding?为什么需要“Embedding模型”?
RAG中检索(Retrieval)的详细过程:
简而言之:Embedding模型是用来对你上传的附件进行解析的,将上传的附件转成大模型能理解的数据。
部署的过程非常简单,但是如果不懂用科学的方式下载,这过程非常耗时间,多数时间都是在等下载。
下载地址:https://ollama.com/
直接打开官网下载的方式下载速度非常慢。这里有一个小技巧,复制链接用迅雷下载。
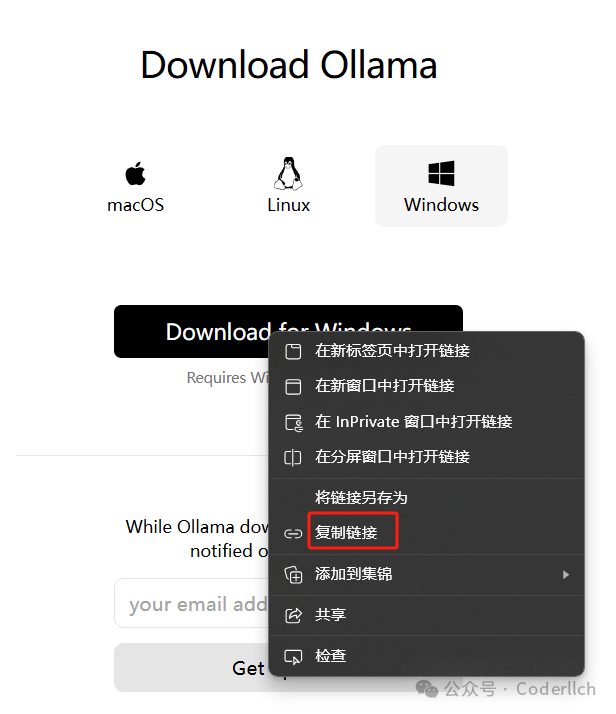
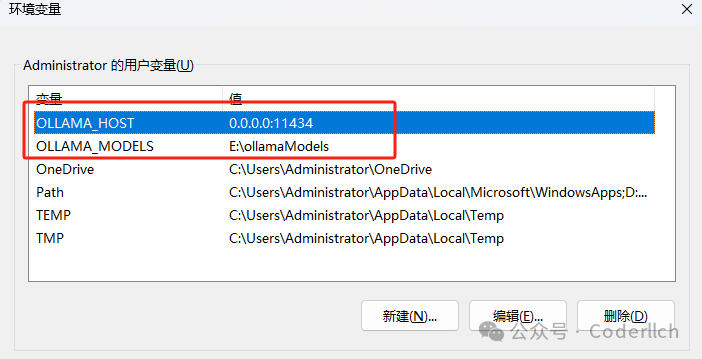
根据电脑配置选择下载不同模型,我这边4060ti 16g+32g内存,这里选择下载14b模型。 cmd窗口,敲入命令,等待拉取模型。
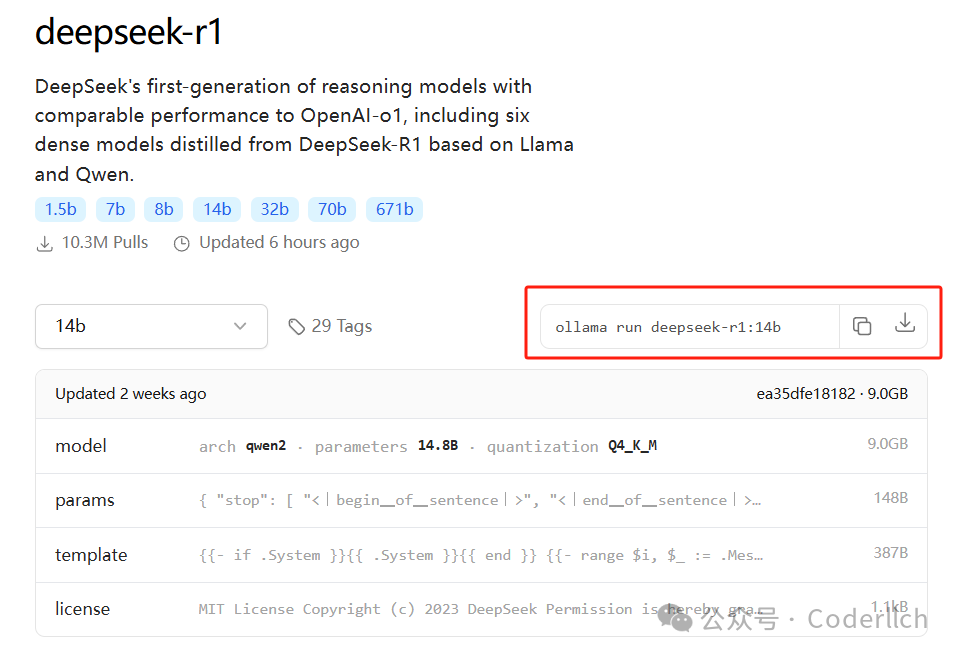
ollama run deepseek-r1:14b
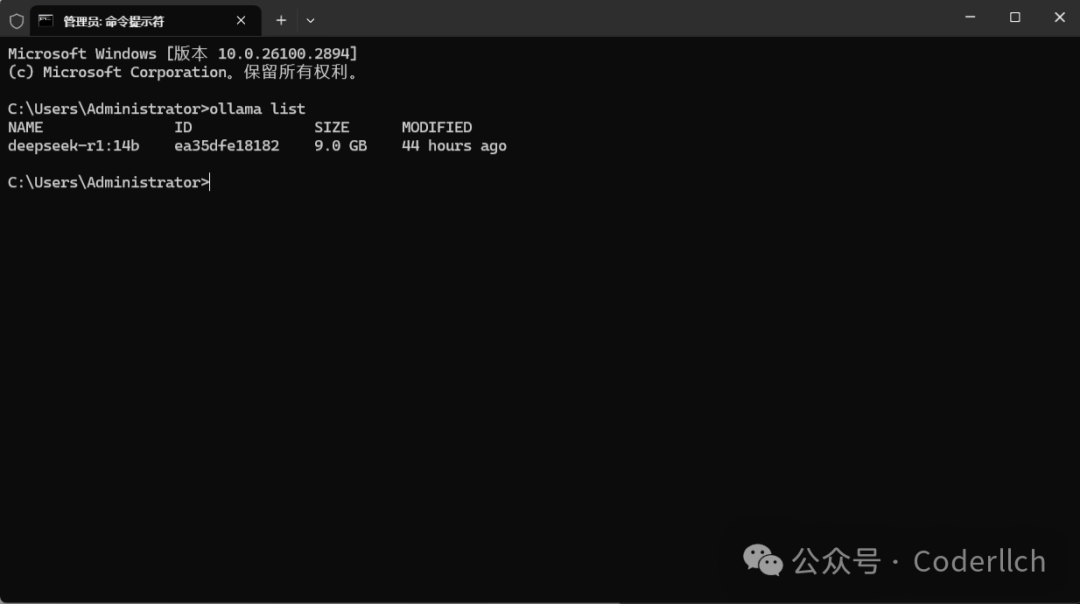
拉取过程比较慢,支持断点续传,速度过慢可以断开重新拉取。拉取完成,通过ollama list可以查看本地已下载模型。
敲入命令ollama run deepseek-r1:14b运行deepseek模型。
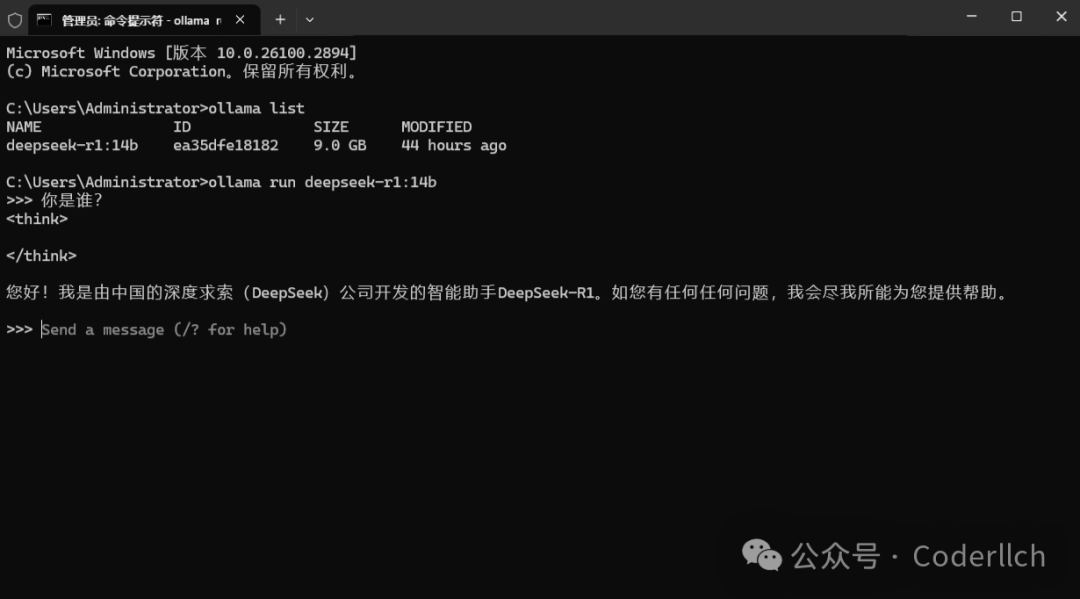
至此,本地部署大模型结束。
https://github.com/n4ze3m/page-assist
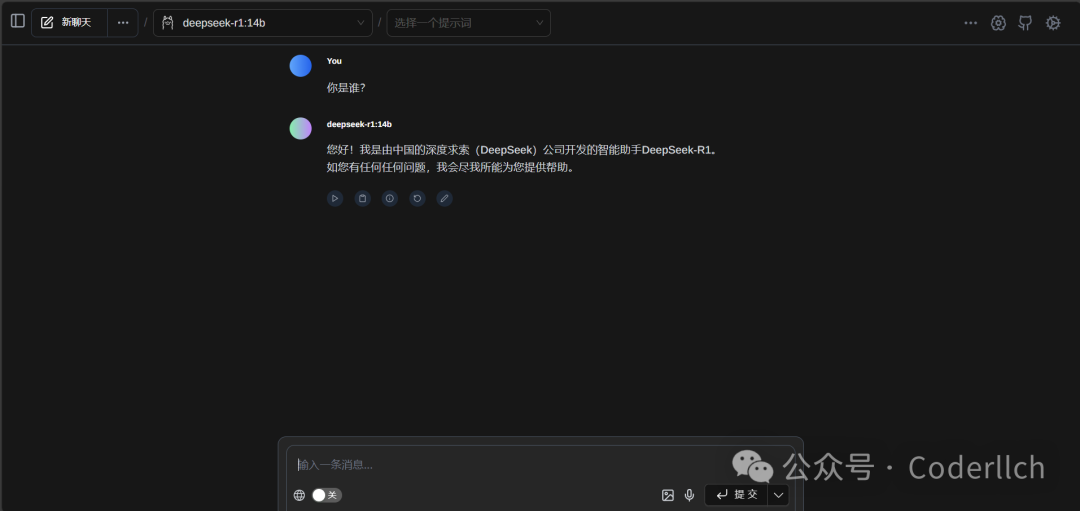
cmd窗口使用不太方便,这里推荐安装Page Assist 一个开源的浏览器扩展,可以给本地 AI 模型提供侧边栏和 Web UI。
https://github.com/ollama/ollama/blob/main/docs/api.md
查看Ollama文档,可以通过api的方式直接调用本地大模型。
curl http://localhost:11434/api/generate -d '{ "model": "deepseek-r1:14b", "prompt": "你是谁", "stream": false}'用Apifox测试接口。
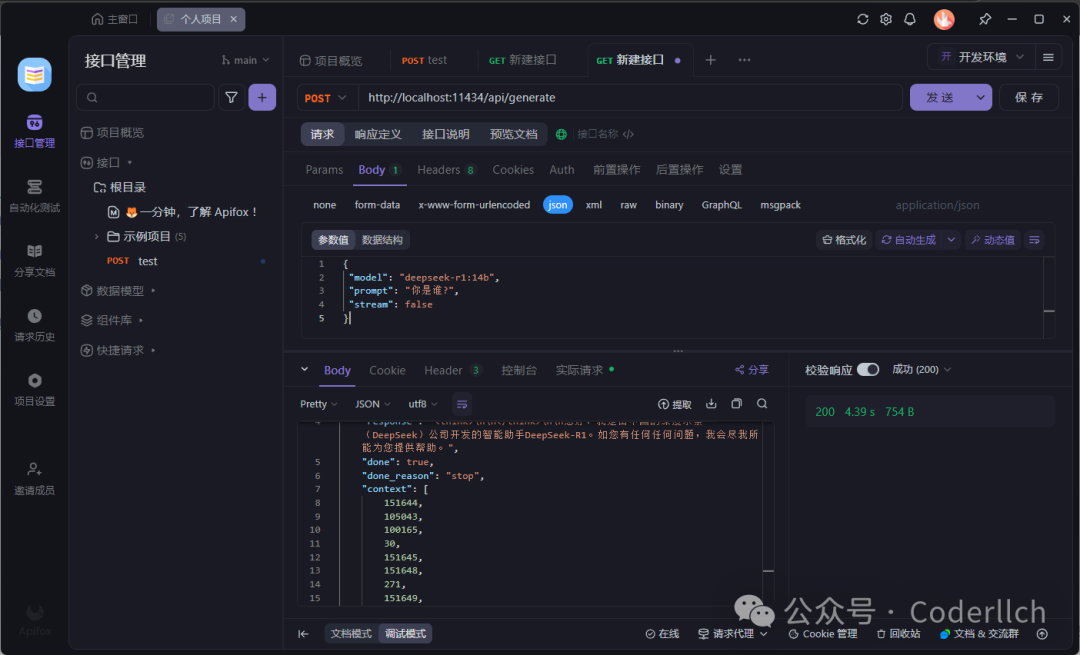
搭建的过程对新手非常友好,DeepSeek的开源特性可以在其基础上进行二次开发,极大降低门槛和成本,还促进了AI技术的快速传播和应用。
本地部署更多的作用是保护敏感数据,并且可以个性化定制,比如搭建私人知识库。如果没有这个需求还是网页版效果更好,毕竟个人搭建高参数模型成本比较高。
RagFlow搭建个人知识库流程放在下一篇笔记。
