由于模型微调对硬件性能要求较高,因此你需要使用PAI的交互式建模(DSW)重新创建一个包含GPU的实例,让你可以更快地完成微调任务。
如果你在本地没有GPU环境或者GPU显存不到30GB,不建议你在本地学习本课程,代码的运行可能会失败
请参考“1_0_计算环境准备”中的步骤一:创建 PAI DSW 实例重新创建一个新的实例,不同之处在于:
确保新的实例与之前创建的实例不重名,如:acp_gpu
资源规格选择免费试用页签中的ecs.gn7i-c8g1.2xlarge(该规格有一个A10 GPU,显存30GB),不用担心,你领取到的免费额度足够支持你完成本节课程以及下一节 部署模型的课程
镜像选择 modelscope:1.21.0-pytorch2.4.0-gpu-py310-cu124-ubuntu22.04(需要将“镜像配置”->”芯片类型“切换为GPU)
完成创建后,当实例状态为运行中时,在 Terminal 中输入以下命令来获取ACP课程的代码:
git clone https://github.com/AlibabaCloudDocs/aliyun_acp_learning.git
在新创建的GPU实例的 Notebook 中重新打开本章节,继续学习接下来的内容。
安装以下依赖:
# 需要安装以下依赖%pip install accelerate==1.0.1 rouge-score==0.1.2 nltk==3.9.1 ms-swift[llm]==2.4.2.post2 evalscope==0.5.5rc1
如何解决数学问题一直是大模型发展的一个重要方向,正好你的智能助手也需要具备基础计算能力。为了方便对模型进行微调,你可以选定一个小参数的开源模型qwen2.5-1.5b-instruct作为你的基准模型。
首先,你需要下载模型,并将其加载到内存中:
# 下载模型参数到 ./model 目录下!mkdir ./model
!modelscope download --model qwen/Qwen2.5-1.5B-Instruct --local_dir './model'from swift.llm import (
get_model_tokenizer, get_template, ModelType,
get_default_template_type
)import torch#你可以根据你的需要修改query(模型输入)# 获得模型信息model_type = ModelType.qwen2_5_1_5b_instruct
template_type = get_default_template_type(model_type)# 设置模型本地位置model_id_or_path = "./model"# 初始化模型和输入输出格式化模板kwargs = {}
model, tokenizer = get_model_tokenizer(model_type, torch.float32, model_id_or_path=model_id_or_path, model_kwargs={'device_map': 'cpu'}, **kwargs)
model.generation_config.max_new_tokens = 128template = get_template(template_type, tokenizer, default_system='')
print("模型初始化完成")可以直接试一试它在数学题上的效果(答案是:可收萝卜648千克):
from swift.llm import inferencefrom IPython.display import Latex, display
math_question = "在一块底边长18米,高6米的三角形菜地里种萝卜。如果每平方米收萝卜12千克,这块地可收萝卜多少千克?"query = math_question
response, _ = inference(model, template, query)
print(query)
print("正确答案是:可收萝卜648千克")
print('-----------大模型回答-------------')
display(Latex(response))
print('------------回答结束--------------')可以发现似乎你的模型并不能很好的计算这个简单的数学问题,模型知道三角形的面积公式,但却无法利用知识准确计算出萝卜的重量。
当然使用RAG的效果是一样的,经过前面的学习,你知道RAG更像是开卷考试,但你从来没有见过数学考试开卷能提升成绩,因为提高数学能力的核心在于提高学生的逻辑推理和计算能力而非知识检索。
所以为了直接提升你答疑机器人在简单数学问题上的能力,你必须使用模型微调来提高模型的逻辑推理能力。(计算能力可以通过引入“计算器”插件来增强)
在传统编程工作中,你通常是知道明确的规则,并将这个规则编写成函数的形式,例如:f(x) = ax。
其中 a 是已知的确定性值(也称为参数或权重)。这里的函数,就是一个简单的算法模型,它能根据输入x来计算(预测)输出y。
然而实际情况中,你更有可能事先不知道明确规则(参数),但可能知道一些现象(数据)。
机器学习的目标,就是帮助你通过数据(训练集),来尝试找到(学习)这些参数值,这一过程被称为训练模型。
要找到最合适的参数,你就需要有办法来度量当前所尝试的参数是否合适。
为了更好理解,可以假设你现在需要评估模型f(x) = ax中的参数 a 是否合适。
你可以用训练集的每一个样本xi对应的实际结果值 yi,与模型预测结果值 f(xi)相减,来评估模型在xi,yi这一条数据上的表现。这个评估误差的函数被称为 Loss Function(损失函数,或误差函数):L(yi, f(xi)) = yi − axi。
直接计算差值时可能会有正有负,这会导致在汇总损失时产生正负值相互抵消,低估了总损失。为了解决这一问题,你可以考虑将差值的平方,作为损失:L(yi, f(xi)) = (yi − axi)2。同时,平方值能够放大误差的影响,有利于你找到最合适的模型参数。
在实际应用中,对于不同的模型,可能会选择不同的计算方法来作为 Loss Function。
为了评估模型在整个训练集上的表现,你可以计算所有样本的损失平均值(即均方误差,Mean Squared Error,MSE)。这种用于评估模型在所有训练样本上的整体表现的函数,被称为 Cost Function(代价函数,或成本函数)。
对于包含 m 个样本的训练集,代价函数可以表示为:J(a) = m1 ∑i=1m (yi − axi)2。
在实际应用中,对于不同的模型,也可能会选择不同的计算方法来作为 Cost Function。
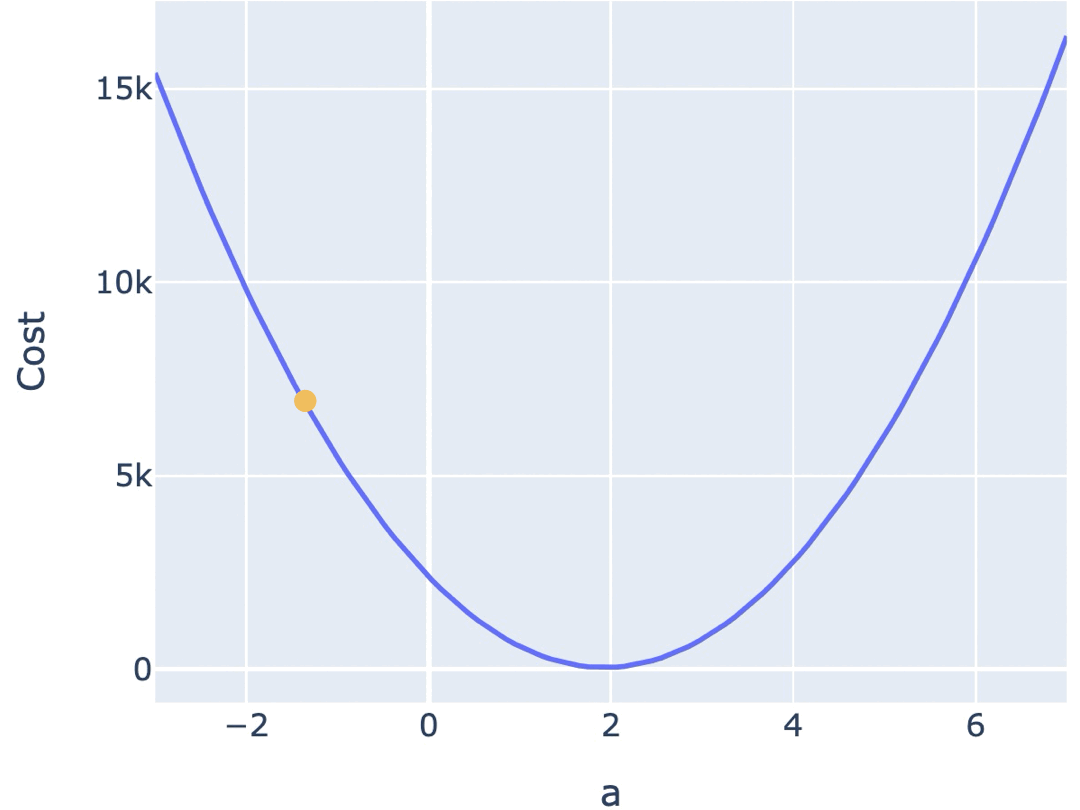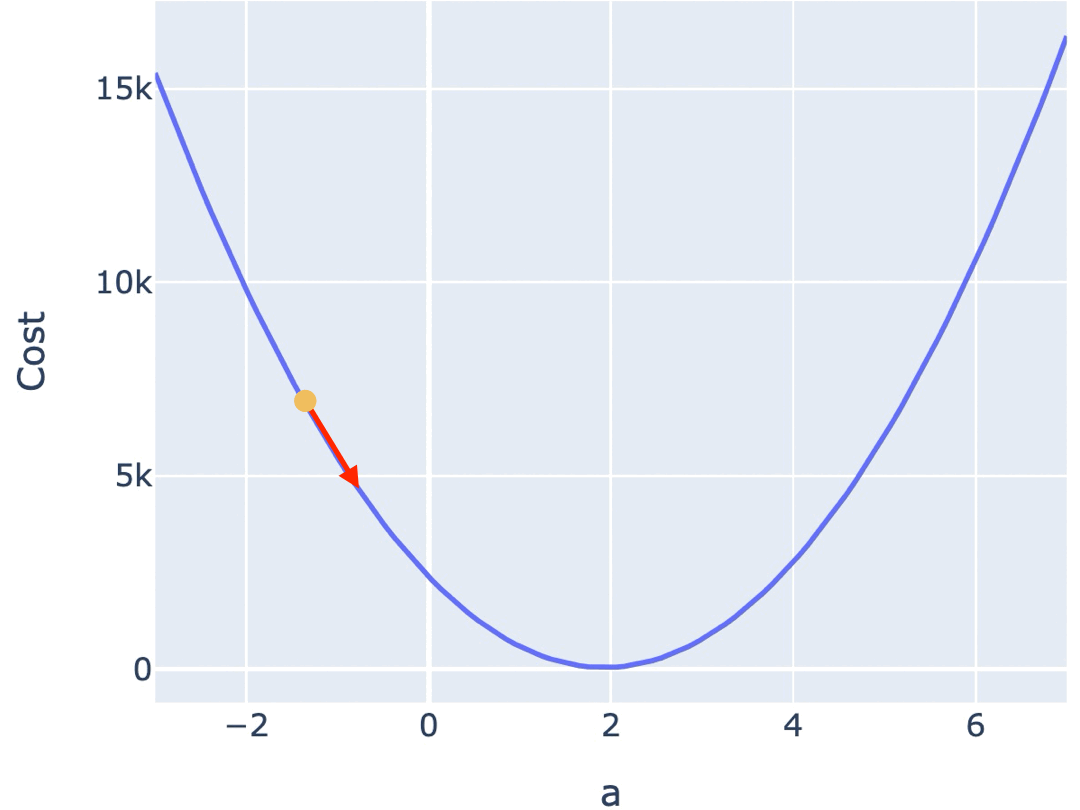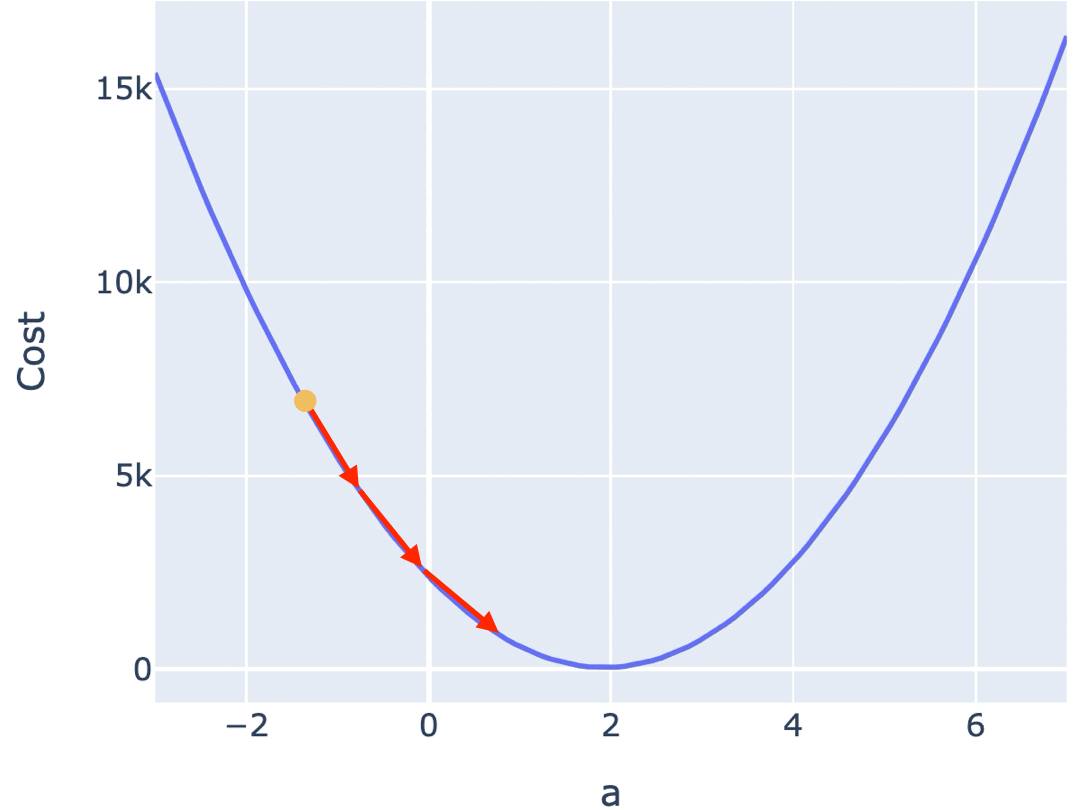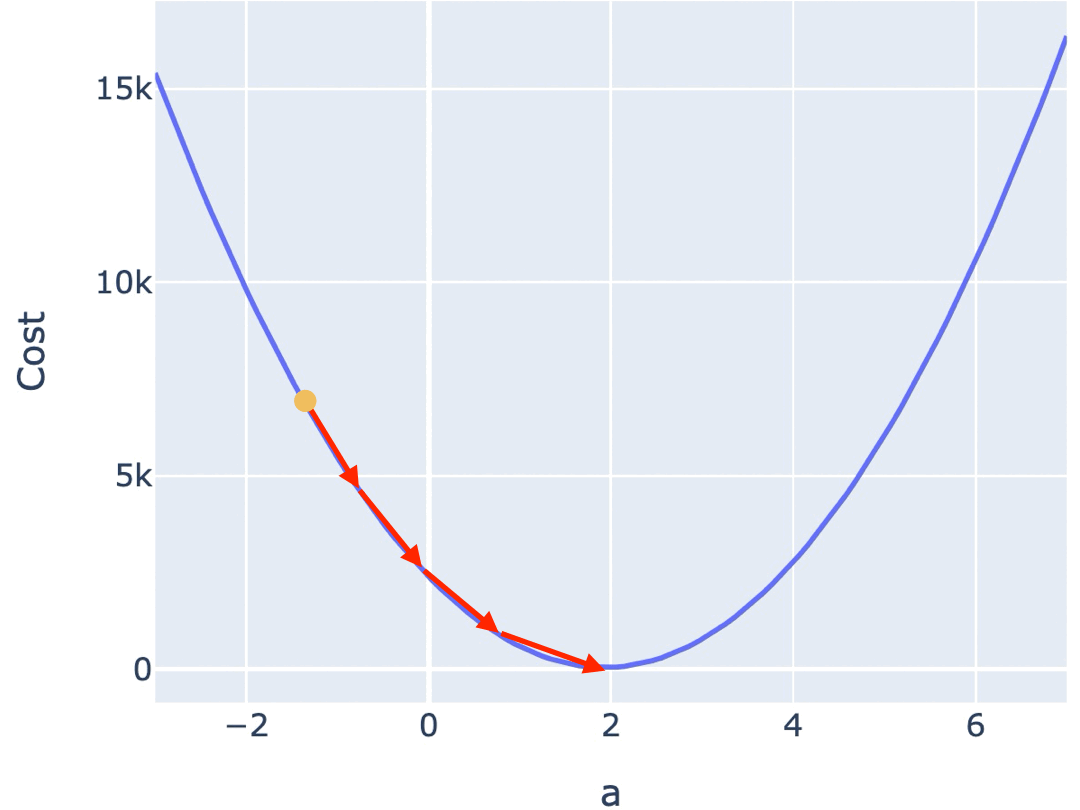
有了 Cost Function,寻找模型合适的参数的任务,就可以等效为寻找 Cost Function 最小值(即最优解)的任务。找到 Cost Function 的最小值,意味着该位置的参数 a 取值,就是最合适的模型参数取值。
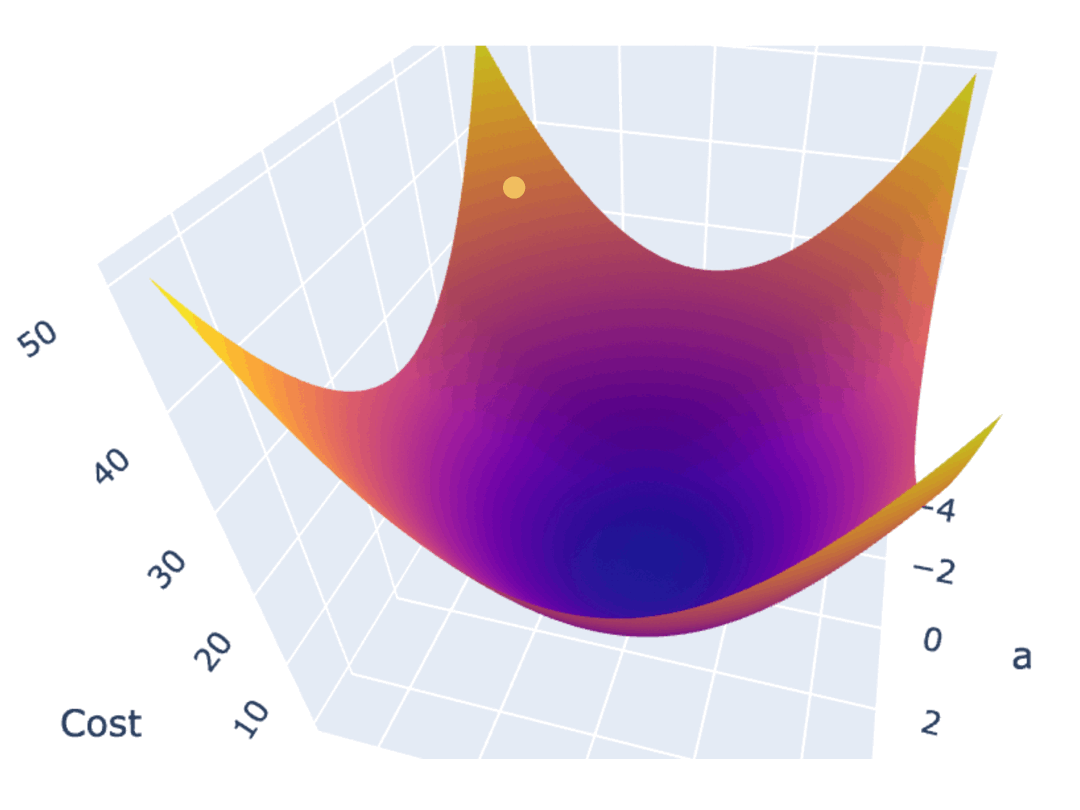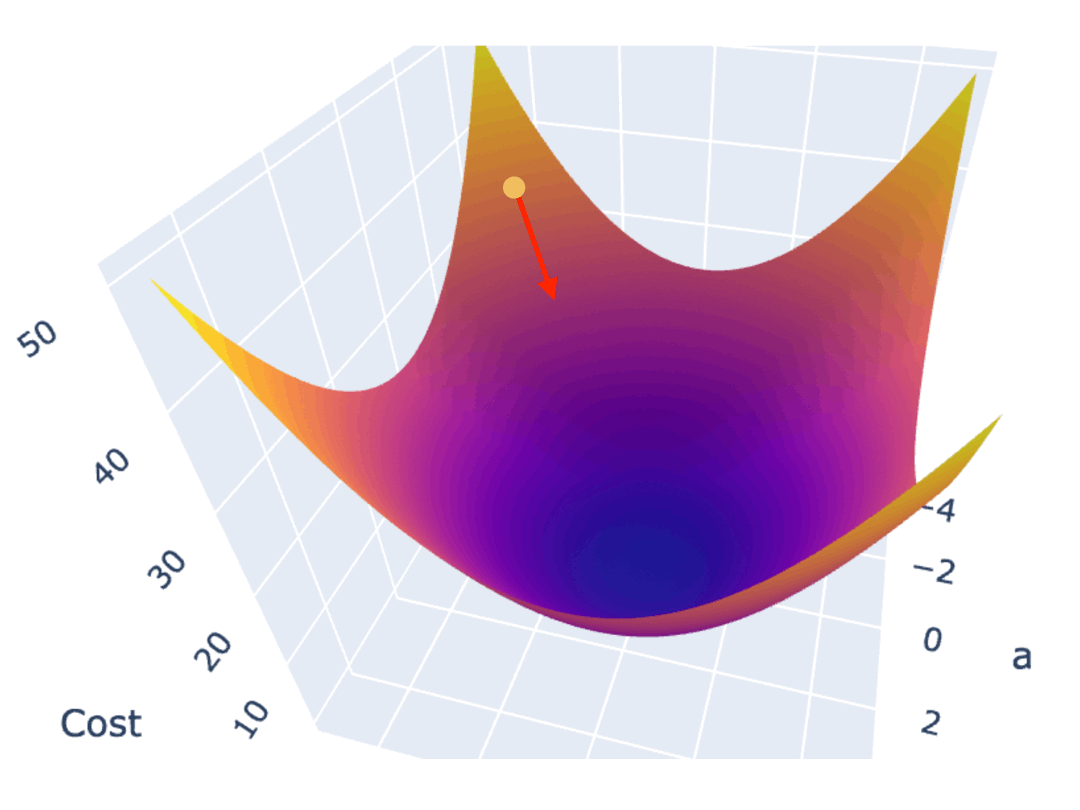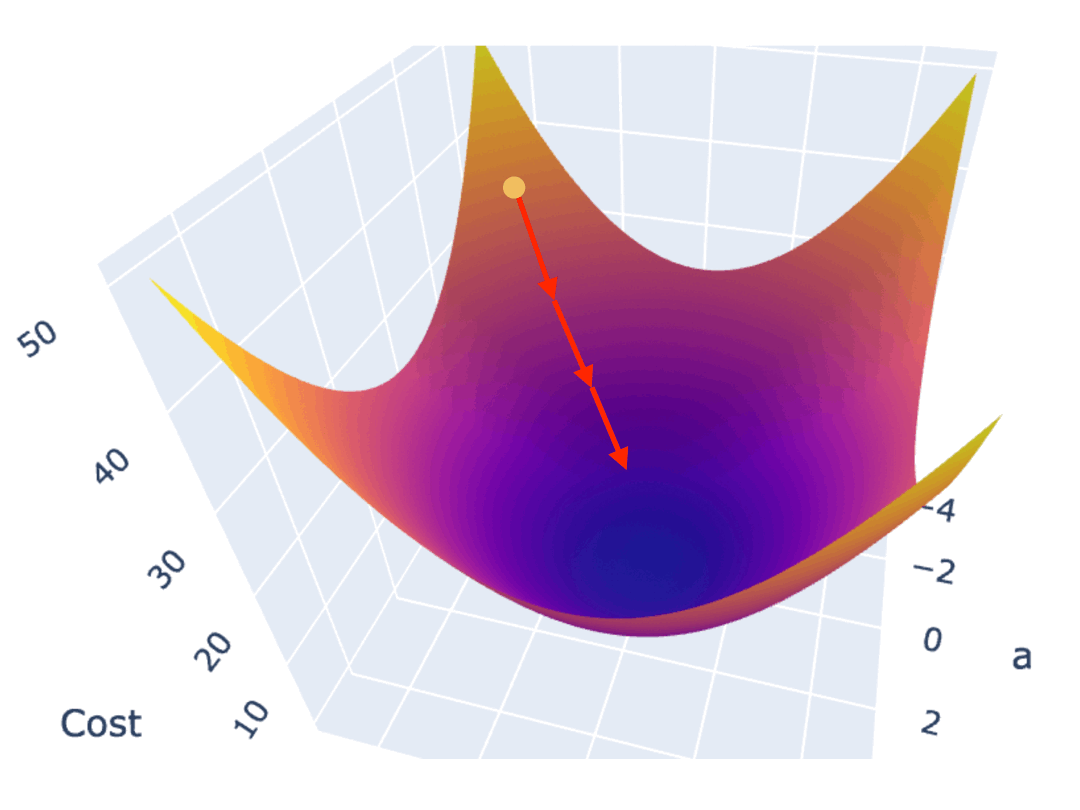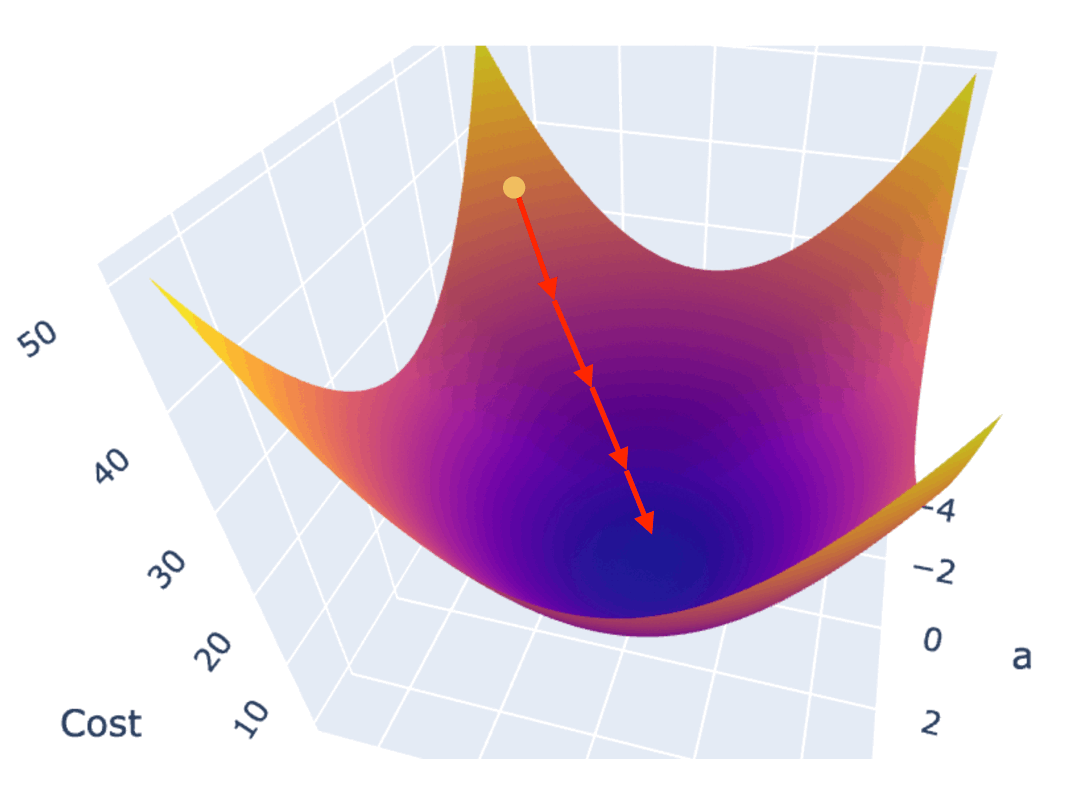
如果将 Cost Function 绘制出来,寻找最优解的任务,其实就是寻找曲线或曲面的最低点。

实际项目中,人们经常会将代价函数、损失函数两个概念混用,在后续内容中的代码,我们也会沿用这一工程习惯,将代价函数称为损失函数(loss function)。
在前面的曲线中,你可以肉眼观察到最低点。但在实际应用中,模型通常参数很多,其 Cost Function 通常是高维空间中的复杂曲面,无法通过直接观察来找到最优解。因此,你需要一种自动化的方法,来寻找最优参数配置。
梯度下降算法是最常见的方法之一。一种常见的梯度下降算法实现是,先在曲面(或曲线)上随机选择一个起点,然后通过不断小幅度调整参数,最终找到最低点(对应最优参数配置)。
训练模型时,你需要训练程序能自动地不断调整参数,最终让 Cost Function 的值逼近最低点。所以梯度下降算法,需要能自动地控制两点:调整参数的方向,以及调整参数的幅度。
如果 Cost Function 是一条 U 型曲线,可以很直观地看到,参数的调整应该是朝着曲线斜率绝对值变低的方向,也就是越来越平坦的方向。

如果 Cost Function 是一个三维坐标系下的曲面,参数的调整方向,同样是朝着越来越平坦的位置。但曲面的某一点上,下降的方向并不唯一。为了尽快地找到最低点,你应该朝着最陡峭的方向移动。

在数学中,梯度指向了以曲面上的某个点为起点,上升最快的方向,其反方向则是下降最快的方向。
为了在最短时间内找到曲面最低点,调整参数的方向,应该朝着梯度的反方向,也就是上面两个图中的绿色箭头方向。
对于二维坐标系的曲线 f(a),某点的梯度就是该点的斜率。
对于三维坐标系里的曲面 f(a,b),某点的梯度是由该点在 a、b 轴方向上的斜率值组成的二维向量。这表明了函数在各个输入变量方向上的变化率,并指向了增长最快的方向。计算曲面上一个点在某一个轴方向上的斜率的过程,也被称为求偏导。
确定了调整参数的方向后,需要确定调整参数的幅度。
按照固定步长调整参数,是最容易想到的办法,但这可能会导致你始终无法找到最低点,而是在最低附近震荡。
比如下图,你按照固定步长为 1.5 来调整参数,就会出现在最低值附近反复震荡,无法进一步逼近最低点的情况。

为了避免这一问题,接近最低点时,应该调低调整幅度。越接近最低点,斜率会越小,因此你可以不再使用固定步长,而是使用当前位置的斜率作为调整幅度。

但也有些 Cost Function 曲线非常陡峭,直接使用斜率也可能导致你跨过最低点反复震荡。为此,你可以使用斜率的同时,对斜率乘以一个系数,来调节步长。这个系数,被称为 Learning Rate(学习率)。
Learning Rate 的选择,对于训练效果和效率尤为重要:
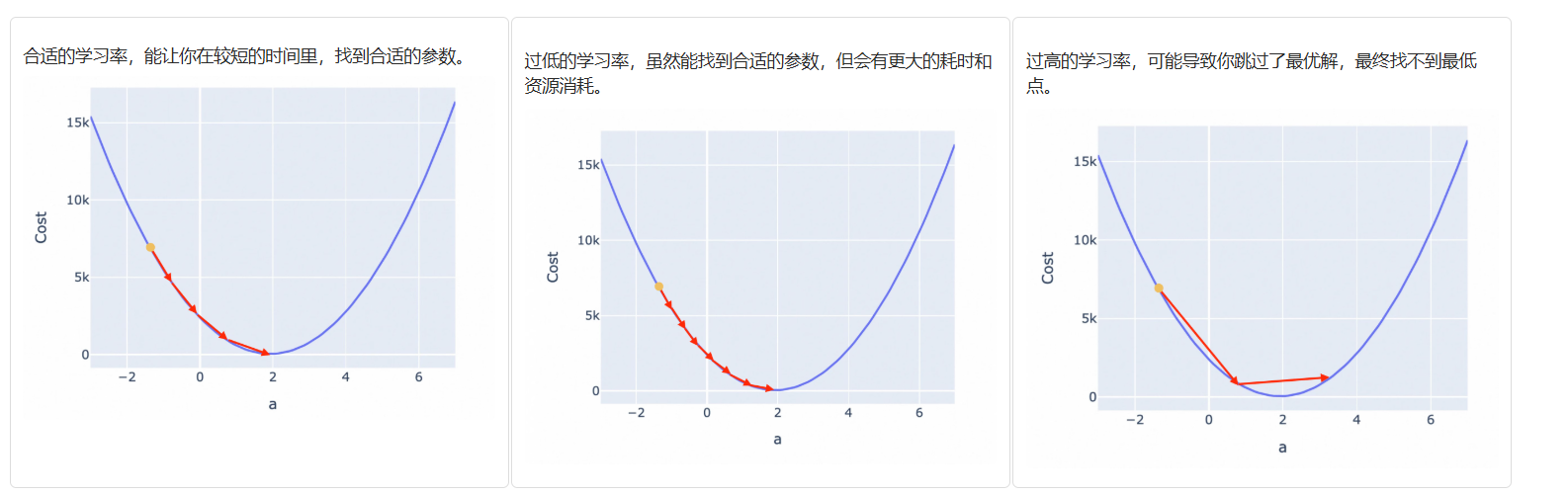
较小的学习率,虽然会让你耗费很多计算资源和时间,但其实有助于你更加逼近最低点。实际的模型训练工程中,也会尝试动态地调整学习率。比如百炼的模型微调功能中,提供了学习率调整策略,它允许你配置学习率线性递减、或者按照曲线来递减。阿里云的 PAI 还提供了 AutoML 工具,它可以帮助你自动找到更合适的 Learning Rate。
在寻找 Cost Function 最低点的过程中,每一次计算梯度(各方向上的斜率),然后根据该梯度更新模型参数,准备进行下一次计算和更新的过程,被称为一个训练步骤(training step)。
前文的介绍中,每个训练步骤是计算某一个点的梯度,然后进行参数更新。你也可以将 batch size 设置为 n ,基于 n 个样本(mini-batch)平均梯度,进行参数更新。
较大的 batch size 能加速训练过程,但对资源消耗也会更大,同时过大的 batch size 也可能导致模型泛化性能下降等问题。
选择合适的 batch size 是一个权衡的过程,它取决于可用的硬件资源、训练时间和期望的模型性能等因素。实践中,通常也需要通过实验来确定最适合特定任务的 batch size。
因为训练集通常数量很大,人们通常不会在对训练集进行完整的迭代后,再使用验证集做评估(evaluation),而是会选择每间隔多少个训练步骤,就用验证集进行一次评估。这个间隔步骤数,通常是通过 eval_steps 参数来控制。
对训练集进行一次完整的迭代,被称为一个 epoch。实际训练过程中,你并不能保证在一个 epoch 内就一定能找到 Cost Function 的最优解(最低点),所以很多训练框架会支持配置训练轮次,如训练框架 swift 中提供的 num_train_epochs 参数。
过小的 epoch 值可能会导致训练结束时,还没有找到最优模型参数。过大的 epoch 值会导致训练时间过长以及资源浪费。
寻找合适的 epoch 的常见方法是早停法(Early Stopping):在训练启动前,并不预设一个 epoch 值(或者设置一个较大值),然后在训练过程中,定期使用验证集评估模型表现。当模型在验证集表现不再提升(或者开始下降)时,自动停止训练。
当然,早停法并不是唯一的解法,业界还有很多其他方法,来确定合适的 epoch 值,如动态调整学习率,根据验证集损失的变化来决定学习率的增减,从而间接影响训练的 epoch 数。
机器学习面临的问题:
在文本生成任务中,输入x和输出y一般都有非常多的维度,你无法直接看出他们之间的规律,该怎么办?
聪明的数学家们找到了一个万能函数逼近器——神经网络(多层),它也成为了当前复杂机器学习任务的基础。
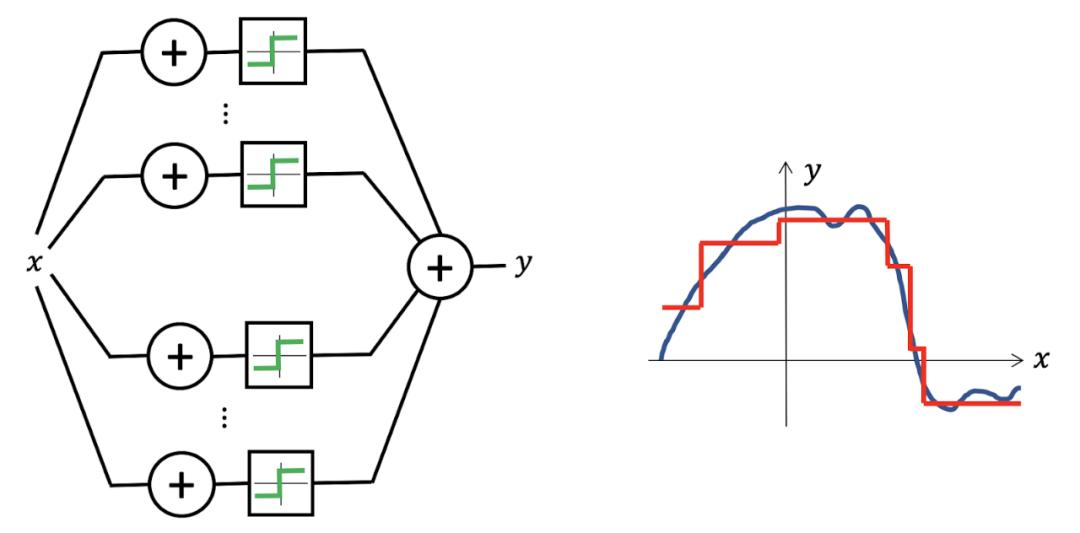
一层神经网络一般表示为Y=σ(W⋅X),大写的输入X和输出Y分别表示它们是多维的,σ是激活函数,W是假定的函数f的参数。k层神经网络可以表示为Y=σ(Wk ⋯ σ(W2 ⋅σ(W1⋅X)))。
激活函数是神经网络中引入非线性变换的关键组件,用于决定神经元是否被激活并传递信息。比如最常用的激活函数ReLU可以写成:
ReLU(input)=max(0,input)=⎩⎪⎪⎨⎪⎪⎧input0当input>0当input≤0
当 input≤0时,神经元不激活;当input>0时,神经元激活,开始向输出传递信息。
一层神经网络展开后可以写成这样:(假设X为 3×2 维矩阵,Y为 2×2 维矩阵)
σ(W2×3⋅X3×2)=σ([ w1,1 w2,1 w1,2 w2,2 w1,3 w2,3 ]×⎣⎢⎡ x1,1x2,1x3,1 x1,2 x2,2 x3,2 ⎦⎥⎤)
=σ([w1,1×x1,1+w1,2×x2,1+w1,3×x3,1w2,1×x1,1+ w2,2×x2,1+w2,3×x3,1w1,1×x1,2+ w1,2×x2,2+w1,3×x3,2 w2,1×x1,2+ w2,2×x2,2+w2,3×x3,2 ])
=⎣⎢⎢⎢⎡ max(0, k=1∑3w1,k×xk,1)max(0, k=1∑3w2,k×xk,1)max(0, k=1∑3w1,k×xk,2) max(0, k=1∑3w2,k×xk,2) ⎦⎥⎥⎥⎤=[ y1,1y2,1 y1,2 y2,2 ]=Y2×2
同时万幸的是,梯度下降法在高维度、复杂的函数上一样有效。

现在你已经有了王牌组合:
能够逼近任意复杂函数的工具——神经网络 + 能够拟合数据规律、学习函数参数的方法 ——梯度下降法
通过前面的学习,你已经了解了模型训练的本质,是寻找最合适的参数组合。
你在最开始下载好的模型,就是预训练好的参数组合。
微调则是在此基础上,进一步训练调整参数,以适应你的目标任务(比如这里的解数学题)。
接下来,以qwen2.5-1.5b-instruct 为例,粗略看下从零训练一个模型的时间和硬件需求。
为了微调大模型,你需要选择如T4、A10、V100、A100、H100等等型号的显卡。其中,T4、A10和V100在国内相对容易租到,且性价比更高;而A100和H100虽然性能更卓越,但成本更高。
显存要求:
1.5B参数占用内存(假设按全精度 FP32 ,单参数占用4字节):1.5∗109∗4/230≈ 5.59GB
一般对模型进行训练时,大概需要模型参数内存的7~8倍,也就是约45GB的显存。这个显存占用基本上超过了大多数显卡的配置,也超过了你的GPU实验环境显存。
假设你在阿里云官网上创建了一个有 8张 V100 显卡的ECS实例,这个实例有256GB的显存,完全满足你的模型对显存的需求。接下来,你可以用下述的方法估算一下训练时间和成本:
训练数据总量:为了满足业务上的精度需要,假设你需要的训练数据量大约相当于两千本红楼梦(假设78万字一本),即大约 15.6亿个token。
单位训练速度:假设你使用的 V100 显卡每秒钟可处理 190个tokens。
单位训练成本:在阿里云官网查到 8张 V100 显卡的ECS实例,每小时价格大约 211元。
那么完成一轮微调训练大概需要 12 天,约 6万元。
训练时间计算如下
训练时间(天)= 8卡∗190tokens/s∗3600秒∗24小时15.6亿Tokens≈12天
相比之下,大模型 LLaMA-65B 的预训练使用了 1.4 万亿个tokens的数据量,采用了 2048 个 A100 显卡,训练速度约为每个GPU每秒处理380tokens,预训练总共花费了 21 天。
训练成本计算如下
训练成本(元)= 8卡∗190tokens/s∗3600秒15.6亿Tokens∗211元/小时≈6万元
相比之下,大模型 LLaMA-65B 的预训练采用了 2048 个 A100 显卡,按当时价格,租用每张 A100 显卡每小时 $3.93 计算,一轮预训练大约需要四百万美元。
因此,你所追求的业务效果和为了达到这个业务效果而准备的训练数据量决定了你做微调需要使用的总算力。而使用更好的显卡 可以显著缩短训练时间,在有些情况下还能节约训练总成本,让你的优化迭代更快。
为了更好的业务效果,你需要首先确保训练数据的质量,再从时间和成本的角度综合考虑租用什么规模的计算集群来完成训练任务。
在实际的模型训练过程中,还面临一个挑战:标注数据的获取成本高昂,尤其是对于特定任务(如医学图像分析或小众语言处理)。你可以尝试对模型进行“预训练”和“微调”分步训练,其中:
预训练:在一个大规模通用数据集上训练模型,使其能够学习到广泛的基础知识或特征表示。这些知识通常是通用的,不针对任何具体任务。预训练不针对特定任务,而是为各种下游任务提供一个强大的初始模型。典型的预训练模型:Qwen2.5-Max、DeepSeek-V3、GPT-4等。
微调:在预训练模型的基础上,使用特定任务的小规模数据集对模型进行进一步训练。其目的是让模型适应具体的下游任务(如医疗、法务等专业领域需求)。
下表展示了预训练与微调的主要区别:
| 特性 | 预训练 | 微调 |
|---|---|---|
| 目标 | 学习通用特征 | 适应特定任务 |
| 数据 | 大规模通用数据 | 小规模任务相关数据 |
| 训练方法 | 自监督/无监督 | 有监督 |
| 参数更新 | 所有参数可训练 | 部分或全部参数可训练 |
| 应用场景 | 基础模型构建 | 特定任务优化 |
值得一提的是,预训练一般通过自监督/无监督方式学习 ,学习的数据来自互联网上的海量文本(如维基百科、书籍、网页),让模型自己从数据中找规律或“猜答案。” 这种学习方式因为其数据无需人工标注,省去了大量人力成本,天然适用于海量数据的学习。
而微调通过有监督学习 ,需要针对特定任务的小规模标注数据(如情感分类的标注评论、医疗文本的标注数据),并用标注数据直接教模型完成任务。这种学习方式由于人工标注成本高,难以扩展为海量数据,因此更适合有明确场景目标的模型训练,所需要的样本数量通常只有几千或几万条。
因此,你可以通过如下方式 快速、低成本 地构建自己的大模型应用:
第一步:直接选择预训练模型(如Qwen、DeepSeek、GPT),这样可以节省从零训练一个模型的综合成本。
第二步:根据自己的实际场景,微调模型,通常只需要构建几千条适用于实际场景的标注数据,因为训练数据总 Tokens 数大大降低,使得训练时间有效缩减,从而进一步降低训练成本。
通过微调可以缩短训练时间,但是微调模型对显存的需求是否也能降低呢?
模型参数量是影响显存需求的主要原因,从调整参数量的大小这个角度,可以把微调分为全参微调与高效微调。
全参微调(Full Fine Tuning) 是在预训练模型的基础上进行全量参数微调的模型优化方法,也就是在上边的模型结构中,只要有参数,就会被调整。该方法避免消耗重新开始训练模型所有参数所需的大量计算资源,又能避免部分参数未被微调导致模型性能下降。但是,大模型训练成本高昂,需要庞大的计算资源和大量的数据,即使是全参数微调,往往也需要较高的训练成本。
高效微调技术(PEFT) 通过调整少量参数,显著降低大模型微调的计算成本,同时保持性能接近全参训练。典型方法包括Adapter Tuning、Prompt Tuning 和 LoRA。其中,LoRA 因仅需训练适配的小参数矩阵(即低秩矩阵,仅需原模型0.1%-1%的参数),成为资源受限场景下的首选方案。以下重点解析 LoRA 如何以极低参数量实现高效微调。
LoRA(Low-Rank Adaptation)低秩适应微调是现在最常用的微调方法,它不关心模型的架构,只是通过矩阵运算将微调需要更新的参数抽象分解成两个小得多的低秩矩阵Ad×r和Br×d用于训练,模型原有矩阵不训练,即Wd×d微调后 = 微调(Ad×r⋅Br×d) + 不变(Wd×d微调前)。
如果你还不太理解低秩分解的过程,那么我们回到神经网络的表达式,并把各个向量、矩阵的维度标好,假设输入X是5维的向量,输出Y是4维的向量,那么W是一个5×4的矩阵,写作W∈R5×4,共包含20个参数。
单层神经网络可比表示为:Y5×1=σ(W5×4⋅X4×1)。
而矩阵的秩通俗一点可以理解为,矩阵的秩R代表的是它的有效信息量。比如这个低秩矩阵虽然有两行三列,但其实用一行(列)向量就能表示其他行(列),所以它的秩(rank)为1。
rank([ 12 2 43 6 ] )=1
而在模型微调中,可以认为绝大部分的信息更新(高秩)在预训练时完成,微调时带来的有效信息量很少(低秩)。 公式可以写成:
W5×4预训练 −W5×4初始=ΔW5×4预训练,rank(ΔW5×4预训练)= 5,而W5×4微调 −W5×4预训练=ΔW5×4微调,rank(ΔW5×4微调)≤2。
而低秩矩阵因为信息密度低,可以进行低秩分解将有效信息分解到两个小得多的矩阵,这里假设rank(ΔW5×4微调)=1:
ΔW5×4微调=⎣⎢⎢⎢⎢⎢⎡ 1 2345 0 0 0 0 0 2 468 10 −1 −2 −3 −4 −5 ⎦⎥⎥⎥⎥⎥⎤5×4=⎣⎢⎢⎢⎢⎢⎡ 12345 ⎦⎥⎥⎥⎥⎥⎤5×1× [ 1 0 2 −1 ]1×4
基于以上的学习成果,以基准模型qwen2.5-1.5b-instruct为例,比如取8=r<<d=1024,我们来对比下实际的参数量。
Wd×d微调后 = 微调(Ad×r∗Br×d) + 不变(Wd×d微调前)
| 方法 | 参数量计算公式 | 参数量 | 节省比例 |
|---|---|---|---|
| 全参数微调 | Wd×d, 1024 ×1024 | 1,048,576 | 0% |
| LoRA微调 | Ad×r 和 Br×d, 1024×8 + 8 ×1024 | 16,384 | 98.44 % |
最后在推理时合并使用 Ad×r、Br×d、Wd×d微调前,可选地提前或动态生成Wd×d微调后。
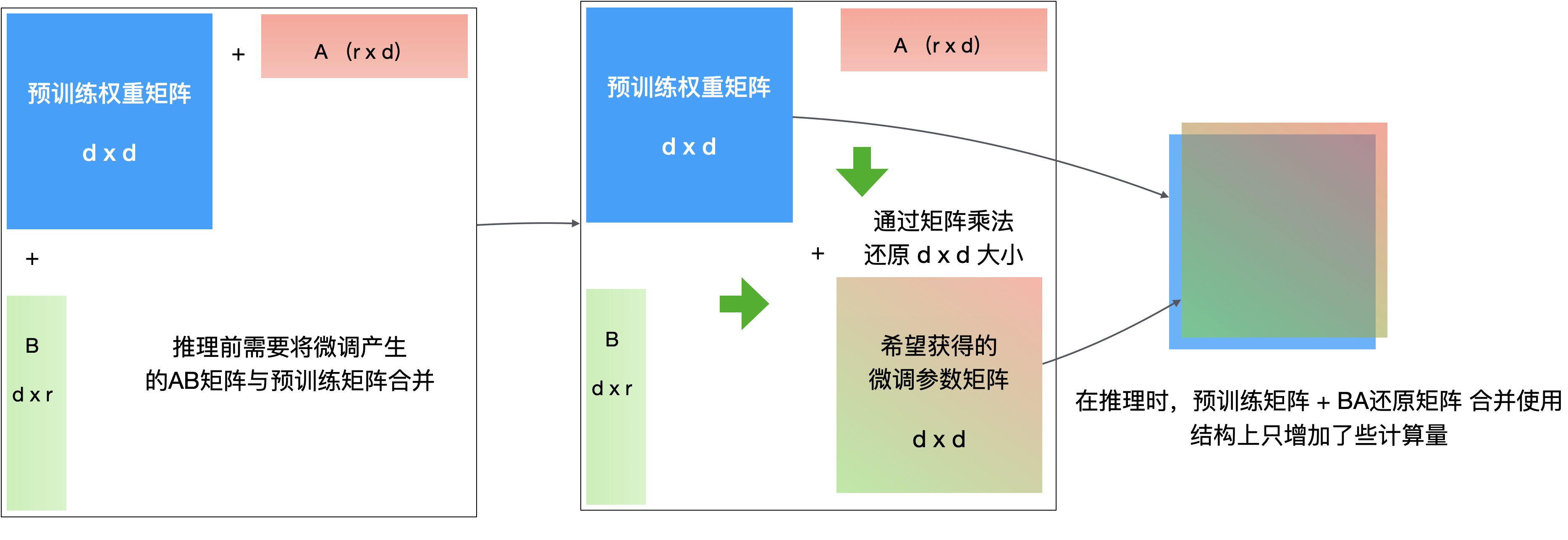
LoRA微调时,主要的可调参数是我们假定的低秩r,它预设得越大,越能捕捉更复杂的特征变化,但模型更难微调,需要更多的显存和训练轮次。
根据经验秩r与训练数据量关系密切:
对于小的训练集(1k-10k样本):建议秩r≤16,避免模型训练轮次太多,而模型去背训练集而不是学习里面的特征。
对于大的训练集(100k+样本):可尝试秩r≥32,可以充分挖掘数据中的潜在模式。
LoRA的作者将多种微调方法在两个数据集上进行了效果对比(横轴是训练参数量,纵轴是训练效果),可以看到LoRA微调的性价比最高。

可见并不是所有方法都能从拥有更多的可训练参数中获益,**并不是训练参数越多效果越好。** 但 **LoRA 方法表现出更好的可扩展性和任务性能**。
训练模型,和人的学习考试过程非常相似。
模型要经过三套题目的考验,产生两个指标,来确定模型训练所处于的状态。它们分别是:
三套题目:
训练集:课程练习册,带详细答案解析,模型会反复练习,并基于损失函数产生
训练损失(training loss)。
训练损失越小,说明模型在你给它的练习册上表现更好。
结合本节 2.1 模型如何学习中讲到的梯度下降方法,模型会基于训练损失来更新自己的参数。
验证集:模拟考试题,模型每学习一段时间,就会测试一次,并基于损失函数产生
验证损失(evaluation loss)。
验证损失就是用于评估模型训练的效果。验证损失越小,说明模型在模拟考试中表现越好。
测试集:考试真题。模型在测试集上的准确率用于评估最终的模型表现。
模型训练的三个状态:
训练损失不变,甚至变大:说明训练失败。 你可以理解为模型在训练集(练习册)上没有学习到知识,说明模型的学习方法有问题。
训练损失和验证损失都在下降:说明模型欠拟合。
你可以想象成模型在训练集(练习册)上的学习有进步,验证集(模拟考试)的表现也变好了,但还有更多的进步空间。这时候你应该让模型继续学习。
训练损失下降但验证损失上升:说明模型过拟合。
你可以理解为模型只是背下了训练集(练习册),在模型考试中遇到了没背过的题反而做不来了。这种场景需要通过一些方法去抑制模型的背题倾向,比如再给它20本练习册,让它记不住所有的题,而是逼它去学习题目里面的规律。
在开始模型微调前,先来看看基准模型在测试集上的表现如何。
import jsonfrom IPython.display import Markdown
sum, score = 0, 0for line in open("./resources/2_7/test.jsonl"): # 读取测试集中的问题
math_question = json.loads(line)
query = math_question["messages"][1]["content"] # 使用基准模型推理
response, _ = inference(model, template, query) # 获取正确答案
ans = math_question["messages"][2]["content"]
pos = ans.find("ans")
end_pos = ans[pos:].find('}}')
ans = ans[pos - 2: end_pos + pos + 2] # 整理输出
print(("========================================================================================"))
print(query.split("#数学题#\n")[1])
print("问题答案是:" + ans)
print("-----------模型回答----------------")
display(Latex(response))
print("-----------回答结束----------------") # 计算模型得分
if ans in response or ans[6:-2] in response:
score += 1
print("模型回答正确") else: print("模型回答错误")
sum += 1# 总结display(Markdown("模型在考试中得分:**" + str(int(100*score/sum)) + "** 分"))基准模型在考试中经常中途放弃推理,难以给出正确答案,这种表现不仅印证了题目难度超出其处理能力,更揭示了提示工程难以奏效的根本原因——模型本身缺乏相应解题能力。只有通过模型微调。
这里使用 ms-swift(Modelscope Scalable lightWeight Infrastructure for Fine-Tuning)框架,它是阿里魔搭社区专门为模型训练开发的开源框架,该框架支持350+ LLM和90+ MLLM(多模态大模型)的训练(预训练、微调、对齐)、推理、评测和部署。
而且 ms-swift 框架使用非常方便,在每次计算验证损失(evaluation loss)时,框架会自动保存当前训练阶段的模型参数(model_checkpoint),并在训练结束时自动保存训练过程中验证损失最小的参数,也就是下图中的(best_model_checkpoint)。

在接下来的多次实验中,将重点调整学习率 (learning_rate)、LoRA的秩 (lora_rank)、数据集学习次数 (num_train_epochs)三个参数,并替换数据集,展示如何进行LoRA微调,其它的参数的调整是为了方便实验效果呈现,如增加批大小(batch_size)从而缩短训练时间,你可以不用过多关注。
在初次实验中,建议你先按照以下参数设置进行微调,且数据集使用100道由DeepSeek-R1生成的题解进行训练,以便后续实验环节中通过参数优化提升训练效果:
| 参数 | 参数值 |
|---|---|
| 学习率 (learning_rate) | 0.1 |
| LoRA的秩 (lora_rank) | 4 |
| 数据集学习次数 (num_train_epochs) | 1 |
| 数据集位置(dataset) | 数据集位置: 当前目录/resources/2_4/train_100.jsonl |
| 可以调整所有的参数自由尝试,但根据展示效果和显存限制,有这些限制 | batch_size <= 16 (显存限制) max_length <= 512 (每条训练数据的最大长度,显存限制) lora_rank <= 64 (LoRA的秩,显存限制) eval_step <= 20 (方便展示) |
开始实验:
ms-swift 框架的微调模块默认使用 LoRA 微调所以实验中不需要显式地声明微调方法。
同时框架会在训练过程中智能地减少实际学习率,保证模型不会总是跳过最优解。
%env CUDA_VISIBLE_DEVICES=0%env LOG_LEVEL=INFO !swift sft \ --learning_rate '0.1' \ --lora_rank 4 \ --num_train_epochs 1 \ --dataset './resources/2_7/train_100.jsonl' \ --batch_size '8' \ --max_length 512 \ --eval_step 1 \ --model_type 'qwen2_5-1_5b-instruct' \ --model_id_or_path './model'
| Training loss 图片 | evaluation loss 图片 |
|---|---|
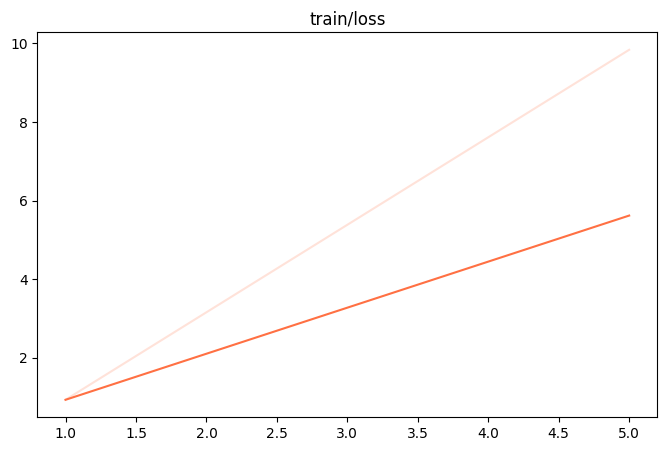 |  |
| 观察指标(训练损失、验证损失): | 训练损失增大、验证损失增大 |
|---|---|
| 训练状态: | 训练失败 |
| 原因分析: | 很有可能是学习率过高,导致模型参数在最优解附近反复横跳,无法找到最优解,训练失败。 |
| 调整逻辑: | 大幅降低学习率至0.00005,让模型以更小步幅“谨慎学习”。 |
| 参数 | 旧参数值 | 新参数值 |
|---|---|---|
| 学习率 (learning_rate) | 0.1 | 0.00005 |
%env CUDA_VISIBLE_DEVICES=0%env LOG_LEVEL=INFO !swift sft \ --learning_rate '0.00005' \ --lora_rank 4 \ --num_train_epochs 1 \ --dataset './resources/2_7/train_100.jsonl' \ --batch_size '8' \ --max_length 512 \ --eval_step 1 \ --model_type 'qwen2_5-1_5b-instruct' \ --model_id_or_path './model'
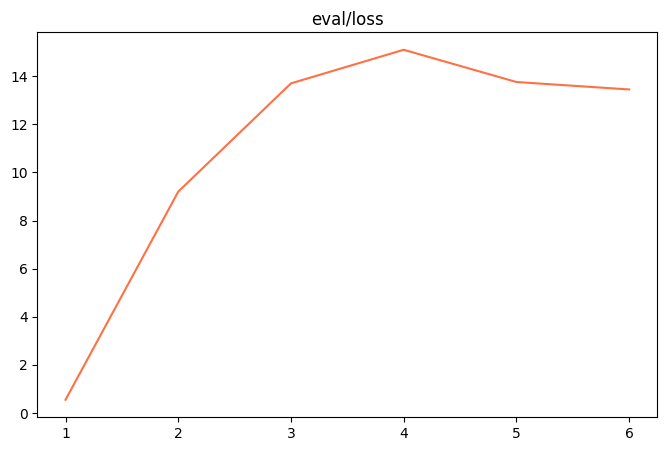
| Training loss 图片 | evaluation loss 图片 |
|---|---|
 |  |
| 观察指标(训练损失、验证损失): | 训练损失减小、验证损失也减小 |
|---|---|
| 训练状态: | 欠拟合 |
| 原因分析: | 欠拟合是在训练中非常常见的现象。 说明在参数不变的情况下,只需要让模型再多训练,就可以训练成功了。 当然也可以修改参数来加速训练过程。 |
| 调整逻辑: | 1. 让模型多训练:数据集学习次数epoch增加至50。2. 将 batch_size调整到最大值16,加速模型训练。 |
| 参数 | 旧参数值 | 新参数值 |
|---|---|---|
| 数据集学习次数 (num_train_epochs) | 1 | 50 |
| batch_size | 8 | 16 |
| eval_step | 1 | 20(优化输出显示) |
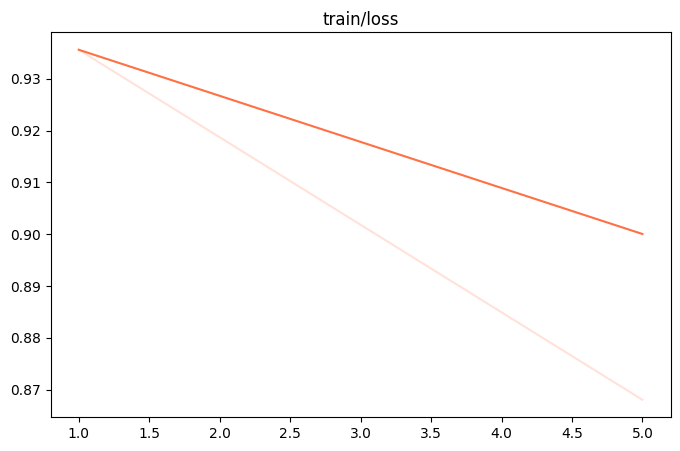
%env CUDA_VISIBLE_DEVICES=0%env LOG_LEVEL=INFO !swift sft \ --learning_rate '0.00005' \ --lora_rank 4 \ --num_train_epochs 50 \ --dataset './resources/2_7/train_100.jsonl' \ --batch_size '16' \ --max_length 512 \ --eval_step 20 \ --model_type 'qwen2_5-1_5b-instruct' \ --model_id_or_path './model'
| Training loss 图片 | evaluation loss 图片 |
|---|---|
 | 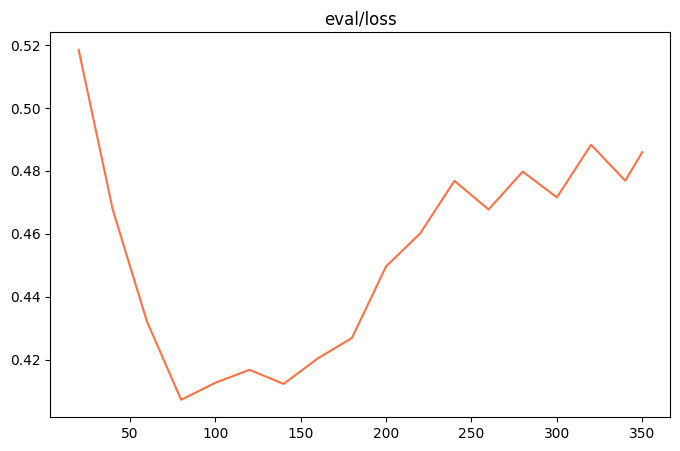 |
| 观察指标(训练损失、验证损失): | 训练损失减小、验证损失先减小后增大 |
|---|---|
| 训练状态: | 过拟合 |
| 原因分析: | 过拟合也是在训练中非常常见的现象。 说明模型在“背题”,没有学习数据集中的知识。 我们可以通过降低数据集学习次数 (epoch) 、增大数据量来让模型“记不住题”。 |
| 调整逻辑: | 1. 数据集学习次数 (epoch) 降低至 5。 2. 将由DeepSeek-R1生成的题解数量扩充至1000条。 数据集位置: 当前目录/resources/2_4/train_1k.jsonl 3. 数据量增加后,根据之前的学习将LoRA的秩提升至16 |
一般来说,在如今的大模型规模下,微调至少需要1000+条优质的训练集数据。低于此数量级时,模型多学几遍就开始“背题”而非学习数据中的蕴含的知识。
| 参数 | 旧参数值 | 新参数值 |
|---|---|---|
| 更换数据集 | 100 条数据 | 1000+ 条数据 |
| 数据集学习次数 (num_train_epochs) | 50 | 3 |
| LoRA的秩 (lora_rank) | 4 | 8(为什么增加请到LoRA介绍中寻找答案) |
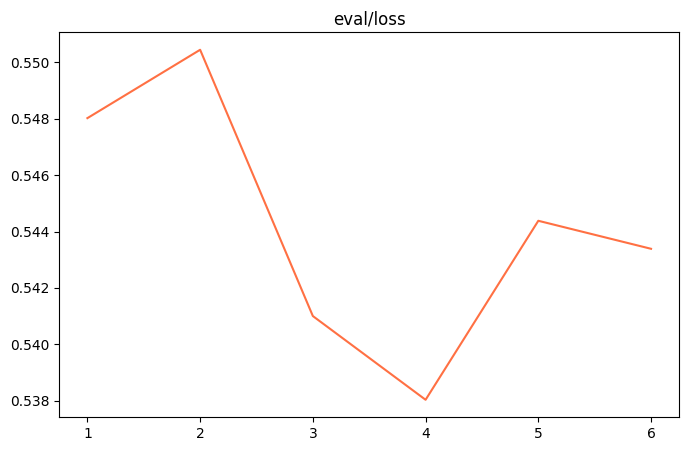
%env CUDA_VISIBLE_DEVICES=0%env LOG_LEVEL=INFO !swift sft \ --learning_rate '0.00005' \ --lora_rank 8 \ --num_train_epochs 3 \ --dataset './resources/2_7/train_1k.jsonl' \ --batch_size '16' \ --max_length 512 \ --eval_step 20 \ --model_type 'qwen2_5-1_5b-instruct' \ --model_id_or_path './model'
| Training loss 图片 | evaluation loss 图片 |
|---|---|
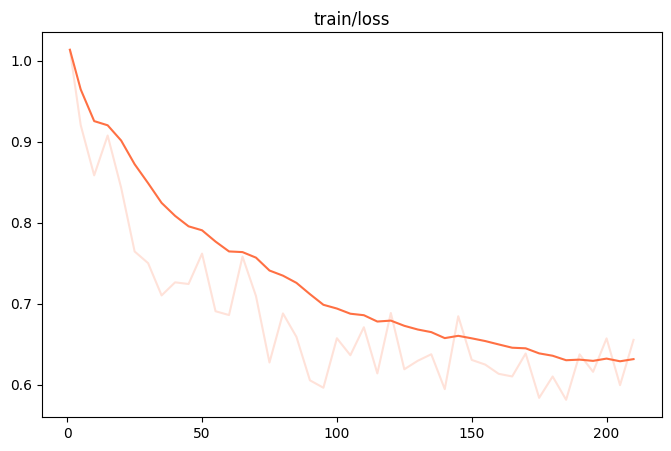 | 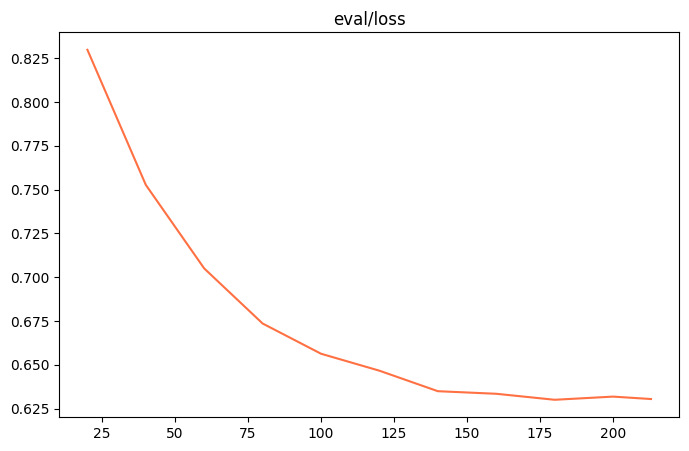 |
| 观察指标(训练损失、验证损失): | 训练损失减小、验证损失也减小 |
|---|---|
| 训练状态: | 欠拟合 |
| 原因分析: | 训练快成功了! |
| 调整逻辑: | 让模型多训练:数据集学习次数 (epoch) 增加至 15。 |
| 参数 | 旧参数值 | 新参数值 |
|---|---|---|
| 数据集学习次数 (num_train_epochs) | 3 | 15 |
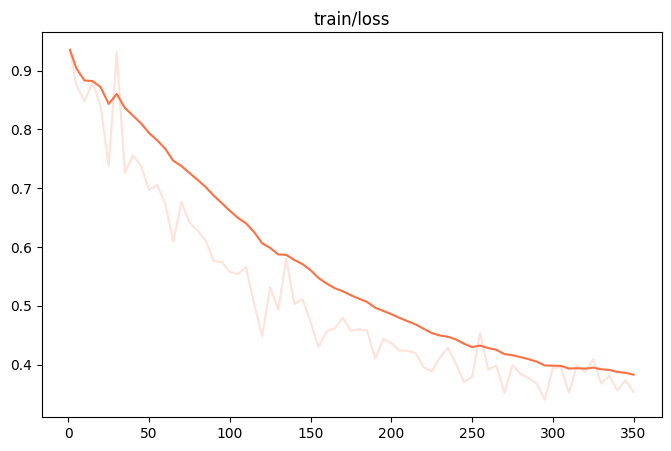
%env CUDA_VISIBLE_DEVICES=0%env LOG_LEVEL=INFO !swift sft \ --learning_rate '0.00005' \ --lora_rank 8 \ --num_train_epochs 15 \ --dataset './resources/2_7/train_1k.jsonl' \ --batch_size '16' \ --max_length 512 \ --eval_step 20 \ --model_type 'qwen2_5-1_5b-instruct' \ --model_id_or_path './model'
| Training loss 图片 | evaluation loss 图片 |
|---|---|
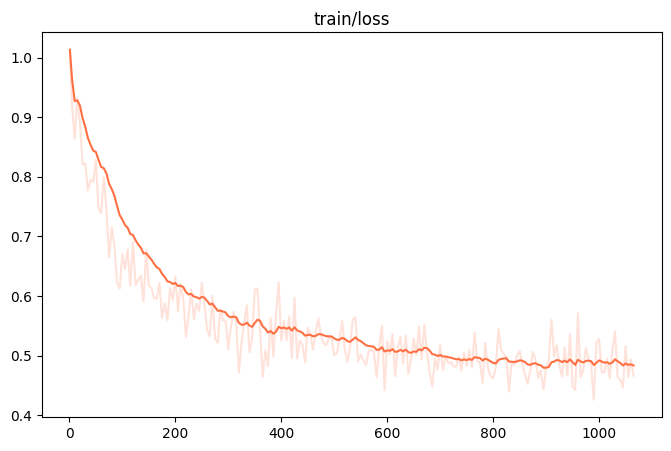 | 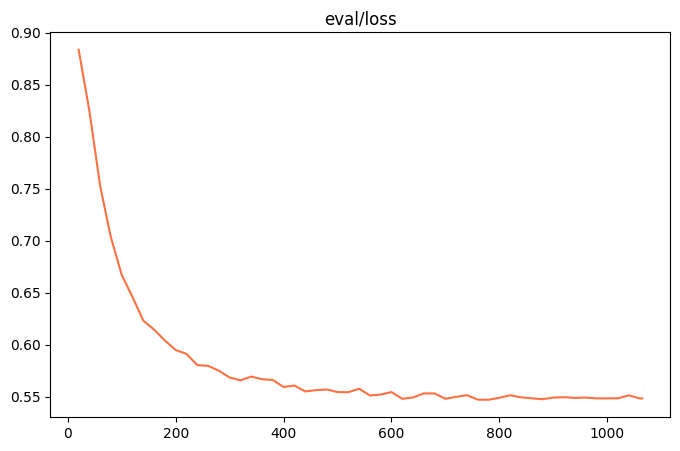 |
| 观察指标(训练损失、验证损失): | 训练损失基本不减小、验证损失也基本不减小甚至还略微升高 |
|---|---|
| 训练状态: | 训练成功! |
微调后一般会保存两个checkpoint文件,分别是best_model_checkpoint(在验证集表现最佳的模型参数)与last_model_checkpoint(微调任务完成时的模型参数)。
这里选取best_model_checkpoint地址替换下面代码中的ckpt_dir,就能调用微调后的模型。
我们先加载模型到内存中:
from swift.tuners import Swift# 请在运行前修改ckpt_dir到正确的位置ckpt_dir = 'output/qwen2_5-1_5b-instruct/vx-xxx/checkpoint-xxx<请修改为lora微调后checkpoint位置>'# 加载模型ft_model = Swift.from_pretrained(model, ckpt_dir, inference_mode=True)
让我们来看看微调后的模型在考试中的表现。
import jsonfrom IPython.display import Markdown
sum, score = 0, 0.0for line in open("./resources/2_7/test.jsonl"): # 读取测试集中的问题
math_question = json.loads(line)
query = math_question["messages"][1]["content"] # 使用微调成功的模型推理
response, _ = inference(ft_model, template, query) # 获取正确答案
ans = math_question["messages"][2]["content"]
pos = ans.find("ans")
end_pos = ans[pos:].find('}}')
ans = ans[pos - 2: end_pos + pos + 2] # 整理输出
print(("========================================================================================"))
print(query.split("#数学题#\n")[1])
print("问题答案是:" + ans)
print("-----------模型回答----------------")
display(Latex(response))
print("-----------回答结束----------------") # 计算模型得分
if ans in response:
score += 1
print("模型回答正确") elif ans[6 : -2] in response:
score += 0.5
print("模型回答正确但输出格式错误") else: print("模型回答错误")
sum += 1# 总结display(Markdown("微调后的模型在考试中得分:**" + str(int(100*score/sum)) + "** 分"))模型训练完成后,有两种方式可以使用训练后的模型:
1. 在调用时动态加载微调模型。
微调后获得的低秩参数矩阵只占20MB的存储空间,这个大小非常便于做增量发布和传播,这也是工程上常用的方法。需要注意的是,用哪个基础模型微调,在加载时就需要指定使用哪个基础模型。
我们在前一小节中,已经通过指定ckpt_dir尝试了这种方法。
2. 将基础模型与微调得到的低秩参数融合,获得一个完整的、更新了参数的模型,再调用融合了的模型。
这里我们介绍第二种方法:融合“微调参数矩阵”与“基础模型参数矩阵”,将微调后的模型参数存储成一个完整的参数矩阵。
通过swift export方法,传入微调模型的路径(建议传入best_model_checkpoint),便可得到融合后的模型。
%env LOG_LEVEL=INFO !swift export \ --ckpt_dir 'output/qwen2_5-1_5b-instruct/vx-xxx/checkpoint-xxx<运行前修改为checkpoint位置>' \ --merge_lora true
日志展示了融合后模型的路径。融合后的完整参数矩阵默认存储在checkpoint目录下。(PAI实验环境完整的模型参数在:output/qwen2_5-1_5b-instruct/vX-XXX/checkpoint-XX-merged)。
在本节课程中,我们学习了以下内容:
理解模型微调的核心价值:通过定向数据注入直接提升模型在数学领域的推理能力,突破提示工程和RAG的局限性。
掌握训练关键参数:学习率控制参数更新幅度,epoch决定数据遍历次数,batch size影响梯度稳定性,并通过损失函数监控训练状态。
认识LoRA高效微调原理:基于低秩矩阵分解降低显存消耗(理论讲解),实践中通过调整lora_rank参数优化训练效果。
完成迭代式调参实验:通过多次学习率/数据量/训练轮次调整,解决欠拟合与过拟合问题,最终显著提升模型解题准确率。
虽然在本教程中你可以使用准备好的数据集,免费体验GPU算力资源进行微调,但在实际生产中,微调并不简单,需综合考虑算力成本、数据规模与质量等因素。 尤其需要关注这几个方面:
提示词工程、RAG等低成本解决方案是否足够处理问题。
数据数量和质量是否满足微调的最低门槛(至少1000条优质数据)。
确保项目预算和专家技术能力匹配,性价比可以接受。
图像分类(如物体识别、医学影像诊断)
微调目的:在预训练模型(如ResNet、ViT)基础上,针对特定图像数据集优化特征提取能力。
关键点:减少数据需求,利用预训练模型的通用视觉知识迁移到细分任务。
目标检测(如自动驾驶、安防监控)
微调目的:调整模型(如YOLO、Faster R-CNN)对特定物体或场景的检测能力。
关键点:优化模型对目标位置和类别的敏感度,降低误检/漏检率。
机器翻译(如领域专用翻译)
微调目的:使通用翻译模型(如mBART、T5)适应专业领域术语和表达习惯。
关键点:解决通用模型在垂直领域翻译中的语义偏差问题。
推荐系统(如电商、内容平台)
微调目的:基于用户行为数据优化推荐模型(如协同过滤、深度排序模型)。
关键点:平衡个性化推荐与冷启动问题,提升点击率/转化率。
Freeze:该方法是最早的PEFT方法。它在微调时冻结模型的大部分参数,仅训练模型中的小部分参数(比如最后几层神经网络),来快速适应特定任务的需求。特点 :
参数效率高(仅训练少量参数)。
适用于任务与预训练目标接近的场景(如文本分类)。
对复杂任务可能效果不足。
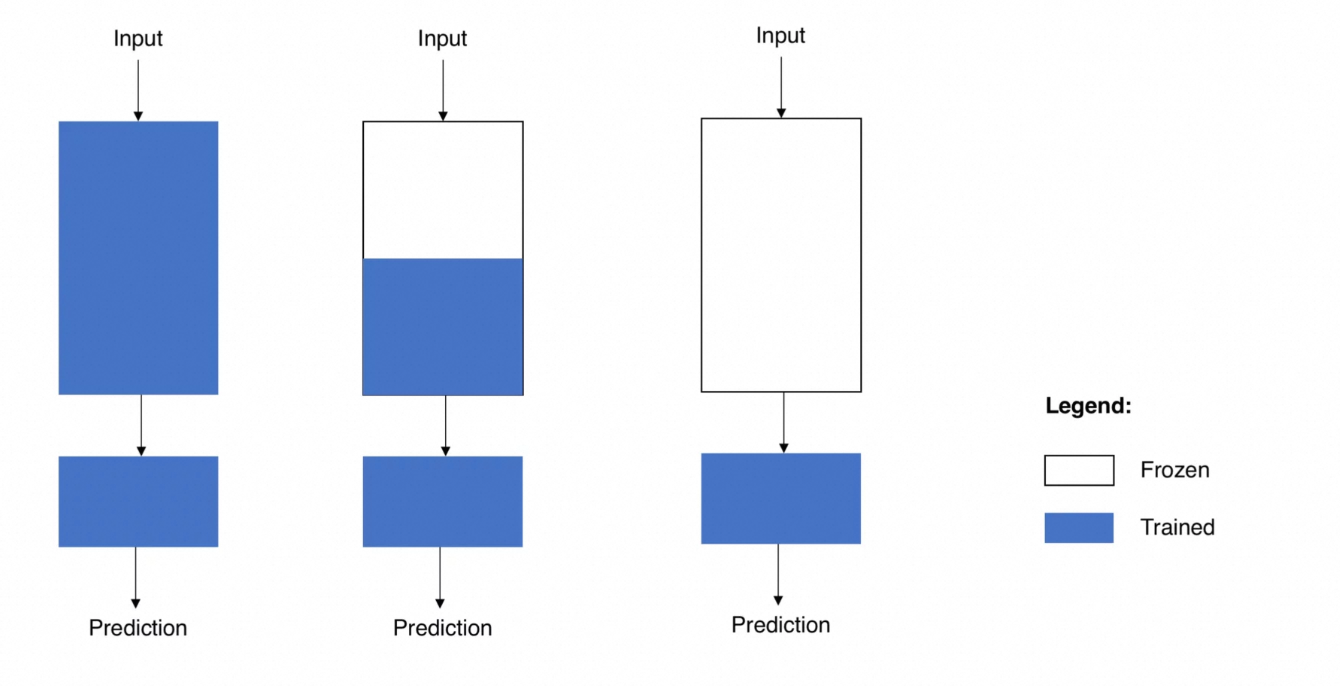
Adapter Tuning:在原有的模型架构上,在某些位置之间插入Adapter层,微调时模型原有参数不会被训练,只训练这些Adapter层,而原先的参数不会参与训练。特点 :
模块化设计,兼容性强。
参数量略高于 LoRA,但效果稳定。
需修改模型结构,推理时需额外计算。

Prompt Tuning:通过优化输入的可学习向量(Prompt)间接控制模型行为,冻结模型参数。特点 :
无需修改模型结构,仅调整输入。
对生成任务(如翻译、对话)友好。
效果依赖提示设计,复杂任务可能不足。
一般来说,在比较复杂的场景中,微调至少需要1000+条优质的训练集数据。构建数据集时,请确认以下几点:
数据质量:确保数据集准确、内容相关,剔除模糊或错误样本。
多样性覆盖:包含任务全场景、多语境及专业术语,避免分布单一。
类别平衡:如果任务涉及多种类别场景,确保各类别样本均衡,防止模型偏向于某一类。
持续迭代:微调是一个迭代过程,根据模型在验证集上的表现反馈,不断优化和扩大数据集。
而如果你在进行模型微调时缺乏数据,建议你使用知识库检索来增强模型能力(如业务文档、FAQ)。
在很多复杂的业务场景中,可以综合采用模型调优和知识库检索相结合的技术方案。
你也可以采用以下策略扩充数据集:
人工标注:由专家扩展典型场景数据。
模型生成:用大模型模拟业务场景数据。
外部采集:通过爬虫、公开数据集、用户反馈等渠道获取。
不同类型的任务评测指标有显著差异,如下是一些典型任务的评测指标:
分类任务:
准确率(Accuracy):正确预测的比例。
精确度(Precision)、召回率(Recall)与F1分数(F1 Score):用于衡量二分类或多分类问题中正类别的识别效果。
文本生成任务:
BLEU (Bilingual Evaluation Understudy) :主要用于机器翻译等自然语言处理任务中,通过比较候选翻译与一个或多个参考翻译之间的n-gram重叠来计算得分。
ROUGE (Recall-Oriented Understudy for Gisting Evaluation) :常用于自动摘要评价,它基于n-gram召回率、精确率以及F-measure。
Perplexity (困惑度):用来衡量概率分布模型预测样本的不确定程度;越低越好。
图像识别/目标检测:
Intersection over Union (IoU):两个边界框相交部分面积与并集面积之比。
mAP (mean Average Precision):平均精度均值,广泛应用于物体检测任务中。
A. LoRA 可以有效降低微调大型语言模型的成本。
B. LoRA 会修改被微调模型的原始权重。
C. LoRA 的实现相对简单,易于集成。
D. LoRA 微调的结果可以方便地回退。
【点击查看答案】
A. 增大 --learning_rate
B. 减小 --learning_rate
C. 增大 --num_train_epochs
D. 减小 --num_train_epochs
【点击查看答案】
你的批评和鼓励都是我们前进的动力。
![]()
公开
注册登录
